什么是关系型数据库|关系型和非关系型数据库的区别?( 二 )
--对简单查询需要快速返回结果的处理 (这里的“简单”指的是没有复杂的查询条件)
这一点称不上是缺点,但不管怎样,关系型数据库并不擅长对简单的查询快速返回结果,因为关系型数据库是使用专门的sql语言进行数据读取的,它需要对sql与越南进行解析,同时还有对表的锁定和解锁等这样的额外开销,这里并不是百思特网说关系型数据库的速度太慢,而只是想告诉大家若希望对简单查询进行高速处理,则没有必要非使用关系型数据库不可 。
---------------------------
NoSQL数据库
关系型数据库应用广泛,能进行事务处理和表连接等复杂查询 。相对地,NoSQL数据库只应用在特定领域,基本上不进行复杂的处理,但它恰恰弥补了之前所列举的关系型数据库的不足之处 。
优点:
易于数据的分散
各个数据之间存在关联是关系型数据库得名的主要原因,为了进行join处理,关系型数据库不得不把数据存储在同一个服务器内,这不利于数据的分散,这也是关系型数据库并不擅长大数据量的写入处理的原因 。相反NoSQL数据库原本就不支持Join处理,各个数据都是独立设计的,很容易把数据分散在多个服务器上,故减少了每个服务器上的数据量,即使要处理大量数据的写入,也变得更加容易,数据的读入操作当然也同样容易 。
典型的NoSQL数据库
临时性键值存储(memcached、Redis)、永久性键值存储(ROMA、Redis)、面向文档的数据库(MongoDB、CouchDB)、面向列的数据库(Cassandra、HBase)
一、 键值存储
它的数据是以键值的形式存储的,虽然它的速度非常快,但基本上只能通过键的完全一致查询获取数据,根据数据的保存方式可以分为临时性、永久性和两者兼具 三种 。
(1)临时性
所谓临时性就是数据有可能丢失,memcached把所有数据都保存在内存中,这样保存和读取的速度非常快,但是当memcached停止时,数据就不存在了 。由于数据保存在内存中,所以无法操作超出内存容量的数据,旧数据会丢失 。总结来说:
。在内存中保存数据
。可以进行非常快速的保存和读取处理
。数据有可能丢失
(2)永久性
所谓永久性就是数据不会丢失,这里的键值存储百思特网是把数据保存在硬盘上,与临时性比起来,由于必然要发生对硬盘的IO操作,所以性能上还是有差距的,但数据不会丢失是它最大的优势 。总结来说:
。在硬盘上保存数据
。可以进行非常快速的保存和读取处理(但无法与memcached相比)
。数据不会丢失
(3) 两者兼备
Redis属于这种类型 。Redis有些特殊,临时性和永久性兼具 。Redis首先把数据保存在内存中,在满足特定条件(默认是 15分钟一次以上,5分钟内10个以上,1分钟内10000个以上的键发生变更)的时候将数据写入到硬盘中,这样既确保了内存中数据的处理速度,又可以通过写入硬盘来保证数据的永久性,这种类型的数据库特别适合处理数组类型的数据 。总结来说:
。同时在内存和硬盘上保存数据
。可以进行非常快速的保存和读取处理
。保存在硬盘上的数据不会消失(可以恢复)
。适合于处理数组类型的数据
二、面向文档的数据库
MongoDB、CouchDB属于这种类型,它们属于NoSQL数据库,但与键值存储相异 。
(1)不定义表结构
即使不定义表结构,也可以像定义了表结构一样使用,还省去了变更表结构的麻烦 。
(2)可以使用复杂的查询条件
跟键值存储不同的是,面向文档的数据库可以通过复杂的查询条件来获取数据,虽然不具备事务处理和Join这些关系型数据库所具有的处理能力,但初次以外的其他处理基本上都能实现 。
三、 面向列的数据库
Cassandra、HBae、HyperTable属于这种类型,由于近年来数据量出现爆发性增长,这种类型的NoSQL数据库尤其引入注目 。
普通的关系型数据库都是以行为单位来存储数据的,擅长以行为单位的读入处理,比如特定条件数据的获取 。因此,关系百思特网型数据库也被成为面向行的数据库 。相反,面向列的数据库是以列为单位来存储数据的,擅长以列为单位读入数据 。
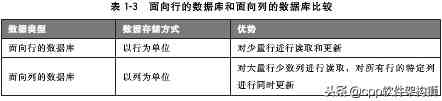
面向列的数据库具有搞扩展性,即使数据增加也不会降低相应的处理速度(特别是写入速度),所以它主要应用于需要处理大量数据的情况 。另外,把它作为批处理程序的存储器来对大量数据进行更新也是非常有用的 。但由于面向列的数据库跟现行数据库存储的思维方式有很大不同,故应用起来十分困难 。
- 私人影院|私人影院是自己选电影吗
- 私人影院|私人影院按人数算还是房间算
- 影院|私人影院有摄像头监控犯法吗
- 春天|2022春天还要冷多久
- 上半年|2022年上半年雨水多不多
- 春天|2022年春天会不会干旱
- 春天|2022年春天是暖春还是冷春
- 春天|2022年春天为什么这么冷
- 春天|2022年春天是几月到几月
- 武汉|武汉樱花在哪个大学