评价方法|简单多指标综合评价三大方法
评价方法(简单多指标综合评价三大方法)
多指标评价常用于需要对一些对象进行比较的场景,在保有明确目的的情况下,通过多个维度的表现数据,赋予不同权重进行综合评判,最终形成排序 。
首先涉及到的就是这些数据的归一化(normalization),或者说标准化,本质上就是去量纲,把量纲理解成计量单位也OK 。这一步的重要性在于,多维度的评判,收集到的多方面数据,横向来看没有强耦合性,性质不同,量纲&数量级则大概率不同,直接用原始数值分析,那你得在不同维度的最终权重赋予上下大功夫,而且也不是很好解释 。
纵向来看,同一维度下不同对象的值极端情况下可能差异巨大,归一化可以减弱这类影响 。总之,去量纲转化为纯数值后,会更方便得进行不同对象之间的差距评估 。
以下是几类方法简介:
一、离差标准化名字很多,也叫线性标准化,最值归一化,min-max法,都是一个意思,即 处理后X = (处理前X – 最小值)/(最大值 – 最小值),这里的最大最小值,指的是同一维度下不同对象的值的集合中的最值 。这样的处理可以把这个集合中的所有数值根据大小差距,映射入[0,1]区间内,也有的处理是最小值默认0,那就是看集合中的值和最大值的比例关系 。
举两个实际例子:
①现在想给a,百思特网b,c三个商家打分,0~10分,有两个维度的数据,各占比40%和60%,这就意味着在维度一上满分是4分 。
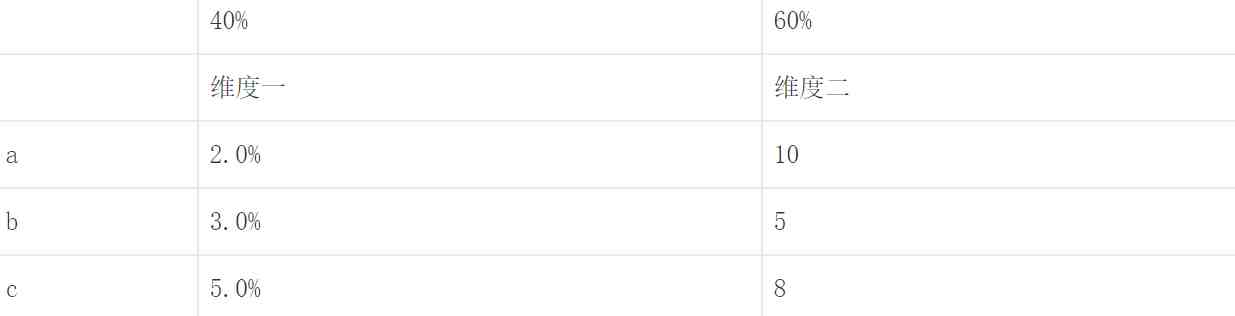
每个维度下最大值得分最高,其余数值按照与最大值的比例得分,最终把两个维度的分数相加,即为总分,如下表 。需要注意的是,并不是所有的维度下,最大值都是最高分,存在值越高分越低的情况,比如差评,针对这种情况在数值处理上要取其倒数 。

【评价方法|简单多指标综合评价三大方法】
②现在要给一个用户推荐一些餐馆,它们的Rank如果除了以往的评价,装潢等,我还要考虑餐馆和用户的距离,或者餐馆和用户搜索的POI的距离 。此时,得分y = 1-(x-min)/(max-min),x = 用户或者POI与餐馆的距离,min = 用户或POI与该城市内餐馆的最小距离,max = 用户或POI与该城市内餐馆的最大距离 。空搜或关键字搜索,不同场景 。二、z-score标准化也叫z标准化,标准差标准化,均值方差归一化 。适用于数量较多,没有明显边界的数据,而且最好满足高斯分布 。公式是处理后X = (处理前X – 均值)/ 标准差 。这里的均值和标准差都是指同一维度下不同对象的值的集合的均值和标准差 。通过这样,就可以把一种分布的数据变换为标准正态分布,均值为0,标准差为1,处理后的数值,符号为正就是超出平均水平,符号为负就是低于平均水平,很清楚 。
处理前:
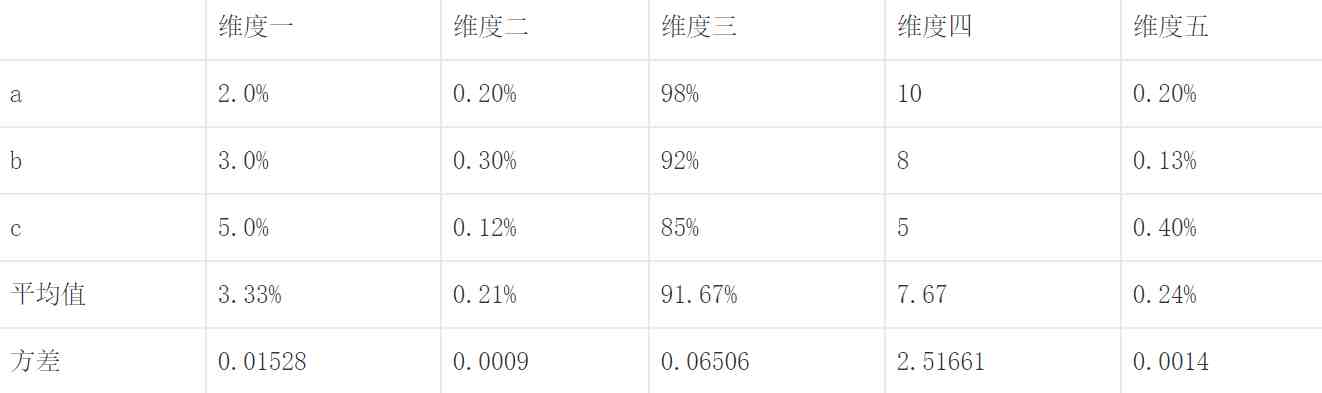
处理后:

同样需要注意的是,如果有的值是越低越好,那么,最终正负号需要做一个相反处理 。
三、非线性标准化这个方法很适合处理极值,要用到这个,就需要看你有没有一个需求,比如,我还是要给用户推荐一批餐馆,排序要去考虑UGC,就是用户评价的数量,但是我研究了一下我所有的餐馆,发现大部分餐馆的评价数都在100~300之间,有一些是1000+,就也不多,但是对于用户来说,评论数无非是一个评价可信的佐证,一个踩坑的概率剪枝,300多条勉强足够了,所以尽管有些餐馆的评论数特别多,它在这一项上的得分也不应该是正常水平的几倍,于是你就需要一个非线性的评价曲线,让评论数超过了一定阈值之后,增长相同的评论数,得分增长越来越低 。这里一般会取用y=a*log10(x)+b的形式,通过调整a与b来根据数百思特网据调整曲线 。
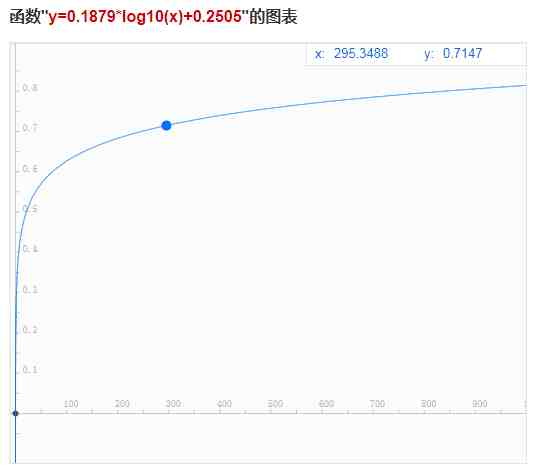
标准化处理时也要考虑数据可能存在的问题,比如由于维度拆分过细,样本量较少,数据异常,可能会导致在单项上某个对象没有数值,针对此类情况,是否考虑在单次评价中将该项上的权重按比例转移?还是有一个兜底分数?等等 。
不同的标准化方式其实适用于不同的业务要求(数据精准,颗粒度等),在多指标评价中你最终可能还会觉得权重的设置起了更重要的作用,但是说到底还是2部分:数据+算式(处理) 。清楚你要评估的对象的哪些方面,清楚地定义口径,是评价体系的客观性的重要体现 。
- 长高|十个长高的科学方法秘诀 怎样长高最快最有效
- 核桃|带壳核桃受潮怎么处理方法
- 巨人的方法经典读后感有感
- 谈恋爱不被骗的实用方法
- 7个小方法,化解你的年末焦虑
- 心灵,放下繁复,回归简单
- 太过主动不是征服男人的最好方法,保持“冷应对”才是
- 简单一点的感情,也许会更加长久一点
- 祛湿|10个男人排湿气最快的方法,男人除湿气妙招
- 最简单的幸福(深刻)