误差分析|如何正确地做误差分析( 二 )
带着这个假说 , 我们下一个需要问的问题是 , 「这个模型经常会犯这种错误吗?」探究猜想的普适性需要研究更多类似的样本 。然而 , 如我们上文说到的 , 如果想要探索整个数据集的话 , 这些非结构化文本中可供利用的特征太少了 , 所以研究人员们通常的做法是手工标注一些错误样本 , 并把它们分为不同的组 。
这种做法的问题在于 , 不同分组的定义是主观的 , 不同的人会提出不同的分组方式 。比如在另一个例子中 , 一个问「when」的问题的标准答案是「在他读大学期间」 , 而模型给出的回答是「1996」 , 是一个错误的年份 。有人会认为这是一个符合干扰词猜想的问题 , 毕竟问题问的是时间 , 和模型给出的回答类型(同样也是时间)是匹配的 。但是也有人会认为它应该属于别的错误类别 , 毕竟标准答案「在他读大学期间」不是一个可以被识别的命名实体 。如果你只是翻看这个错误例子的名称和文本描述的话 , 很有可能你都意识不到会有这种差异 。
实际上 , 论文作者们发现即便只是用简单的法则定义不同的错误分组 , 这种差异性/人与人之间的不一致性也会出现:作者们找来此前曾发表过的一份错误分析中的一个错误类型及其描述 , 然后让现在的专家们重复这个实验 , 结果他们分到这一组的错误数量大为不同 , 差异最小也有 13.8% , 最大甚至有 45.2%;这更明显地体现出了人工标注的模糊性 。
针对这种状况 , 论文作者们提出了第一条原则:必须用明确的描述精确定义错误猜想 。
原则 1:准确为了规避人为主观性、提高准确性 , Errudite 使用了一种任务专用语言(Domain-Specific Language)来量化描述不同的实例 。
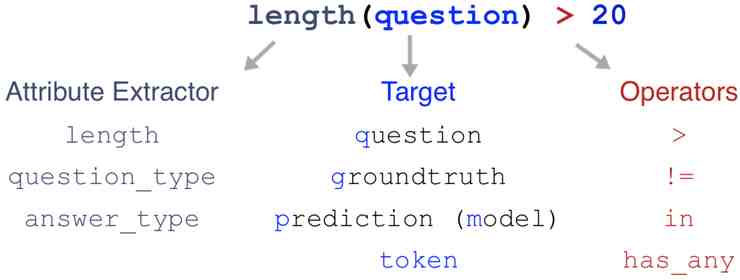
简单来说 , 这种任务专用语言使用了一系列强有力的属性提取器 , 在额外的辅助操作符的帮助下解析具体的错误(属性提取器、目标、操作符三部分) 。比如可以解析一个问题的长度 , 并要求长度大于 20 。这样 , 研究人员们就可以根据特定的模式 , 客观、系统地对大量错误例子分组 , 得出某种错误的准确的出现频率 。比如下图就是用这种语言对「干扰词猜想」的准百思特网确描述 , 也就可以把「在他读大学期间」这个例子排除在这个分类之外 。
原则 2:覆盖所有的数据在 BiDAF 的所有错误中执行了这个过滤器之后 , 一共找到了 192 个例子是符合「干扰词猜想」的 , 也就是说标准答案和错误答案的命名实体类型相同 , 然后模型给出了错误的实体 。值得注意的是 , 在达到了这种准确性的基础上 , 任务专用语言的运用也可以极大地拓展误差分析的规模:相比于常见做法里一共分析 50 到 100 个错误样本 , 现在单个错误类别的样本量都达到了 192 。这也就减小了采样误差 。
总数量方面 , 这 192 个错误样本占到了所有错误总数的 6% , 这个干扰词猜想看来是可以被证实的 。有具体数据以后 , 错误分析的说服力也变强了很多对吧 。
不过 , 当我们执行了所有步骤中的过滤器、构建出了详尽的分组以后 , 我们其实会发现全新的图景:对于全部样本 , BiDAF 能给在 68% 的样本中给出正确的实体;对于标准答案就是一个实体的样本 , 模型的准确率会提高到 80%;当文本中有同一个类型的其它实体的时候 , BiDAF 的准确率仍然有 79%;让它预测一个类型正确的实体的时候 , 它的准确率高达 88% , 要比全部样本的正确率高得多 。这意味着 , 对于实体类型匹配、且有干扰词出现的情况 , 模型的表现还是比整体表现要好 , 这种情况并不是模型表现的短板 。所以 , 如果你只是发现了有某种错误出现 , 然后就决定要先解决这种错误的话 , 你可能需要重新考虑一下 , 因为你很可能忽视了模型表现非常糟糕的情境 。
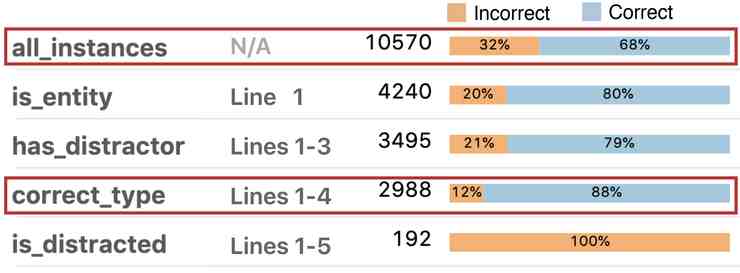
所以 , 这个领域专用语言可以帮助分析整个数据集 , 包括检验没有出错的样本 。这样的误差分析更系统、可以支持更大的规模;相比于只看一小部分样本 , 你得到的结论也可能完全不同 。
- 《中国哲学如何登场》读后感摘抄
- 电视柜|电视柜如何选择尺寸
- 德祐的门店复制模式——如何快速培养人才? 薄荷曼哥
- 如何看出一个女生慢慢不喜欢你了
- 中介|中介如何知道你跳单了
- 如何阅读德里达读后感精选
- 如何阅读福柯的读后感大全
- 猫|如何布置猫的房间
- 专注力:如何高效做事读后感精选
- 如何阅读克尔凯郭尔的读后感大全