机器人定位技术|移动机器人全局定位技术与方法( 三 )
2、右边的部分是把这几个已经初定位的定云进行精定位 。就是把全局定位分解成地图、点云对齐的两步 。是一种利用优化解决全局定位的方法,单优化的过程不是通过经典的解析优化算法,而是通过神经网络来完成优化,效果相当好 。
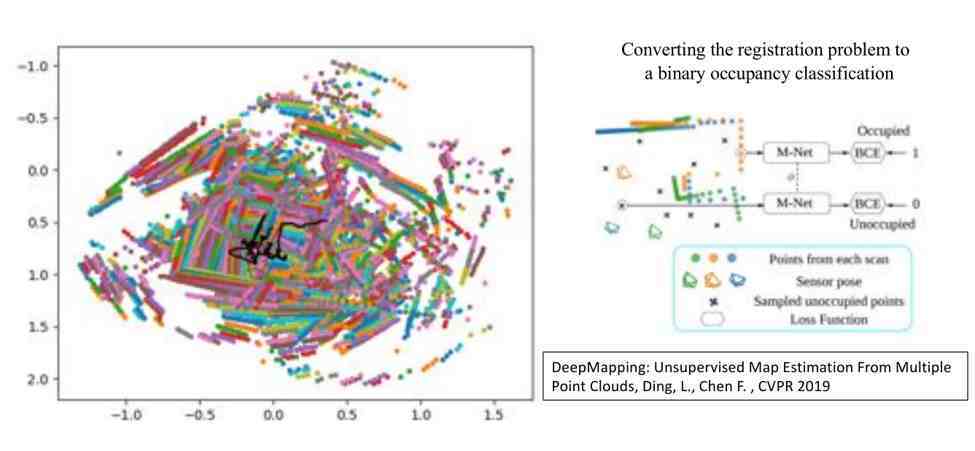
以上介绍的所有方法都是基于二维的点云完成全局的定位,到了10年前,即2010年左右,三维点云、多线激光雷达技术慢慢地成熟,随之而来的是基于三维点云分析方法和移动机器人全局定位方法 。
这篇文章解决了尺度问题:首先对三维多线激光雷达产生的点云进行特征(NARF)提取,把现在观察到的NARF特征跟地图中的NARF特征进行快速匹配,完成全局定位 。
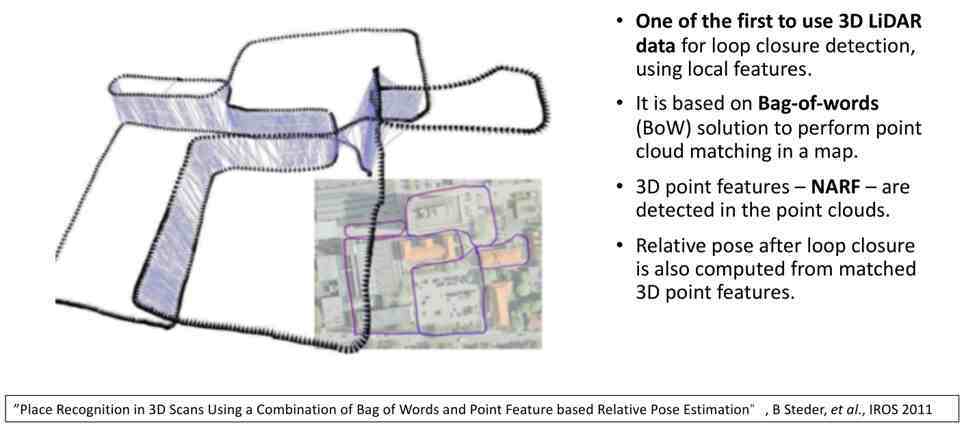
此外,和上一件工作类似,这篇文章介绍了更新颖的三维特征点Gestalt的提取方法,提高辨别力,使得点云匹配的效果非常好 。

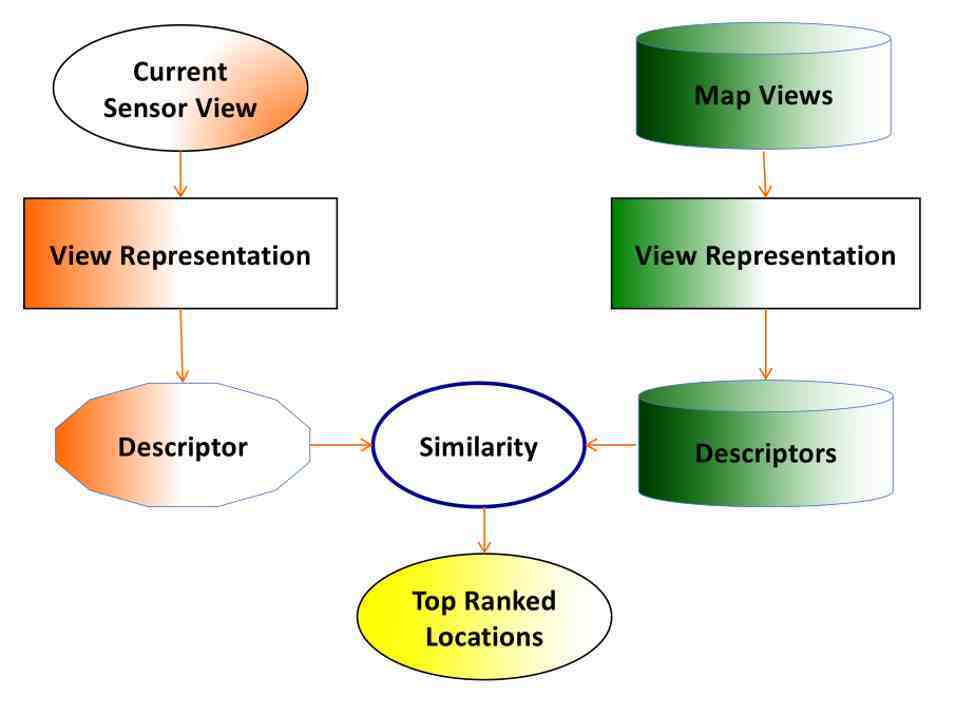
以上的所有的工作都是基于对三维点云中局部特征点的匹配来完成全局定位工作,2016年我有两个学生首次提出了如何产生所谓全局描述符:给定一组由若干个点云组成的地百思特网图,之后对每一个点云进行描述,把地图所有点云变成了描述符;当机器人观察到某一个点云时用同样的方法对其进行刻划,产生描述符 。然后把观察到的描述符和地图中的描述符进行一一匹配之后,进行相似度计算,可以产生当下机器人的位置 。
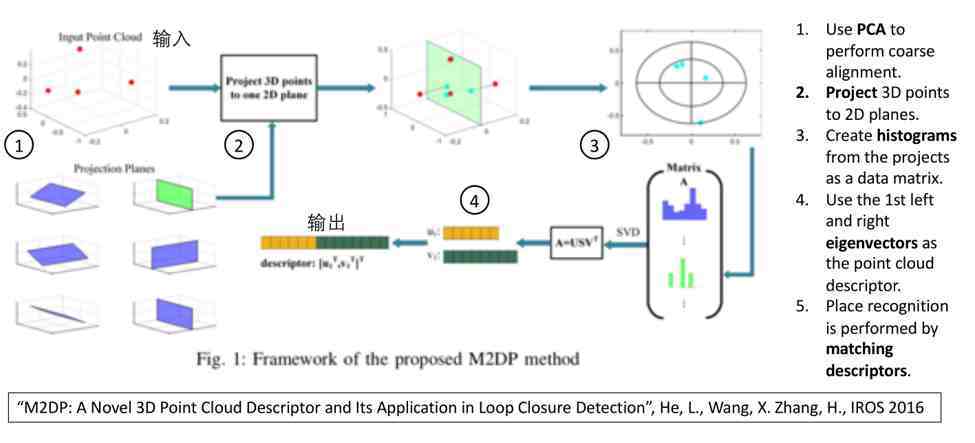
这件工作中描述符是如何产生的呢?
输入是一个点云,输出是向量,该向量描述了点云的特征,产生过程包括若干个步骤 。首先把点云投影到几个特定的二维平面,再产生直方图,直方图拼接构成矩阵,通过对矩阵进行奇异值分解 (SVD)计算该矩阵的左右特征向量,最后把两个对应最大奇异值的左右特征向量拼在一起,构成一个一维的向量作为点云的描述符 。
描述符的代码是开源的:
https://github.com/LiHeUA/M2DP
视频中介绍的是验证实验 (
https://www.youtube.com/watch?v=o87MGK8qQaY) 。工作是在很流行的公共数据集上完成的,左上角是机器人观察到的视觉图像(在定位中没有使用),右上角是不同位置采集的点云,每一个点云都要进行描述符的计算,地图中的不同位置由若干个描述符刻画,当机器人回到曾访问过的某个位置时,对现在观察的描述符和地图中描述符进行相似度计算后,当该相似度超越某个阈值后,就可以完成当下机器人全局定位的工作 。
近两年全景描述符越来越流行了,包括现在用深度学习的方法产生一维的向量,作为全局点云图的刻画,用视觉完成这件事的时候受光照变化影响很大,但是激光雷达产生的点云则对光照变化有更好的鲁棒性,可以有效完成高精度全局地位工作 。
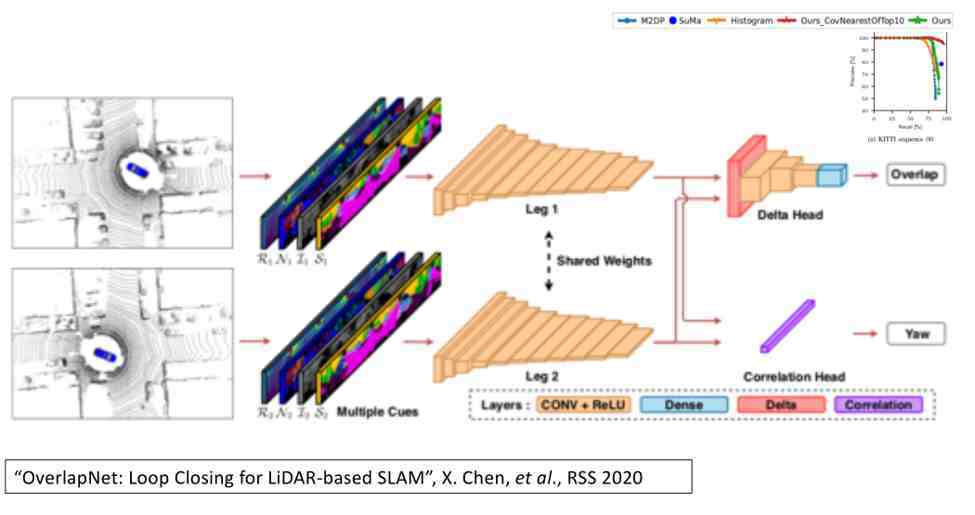
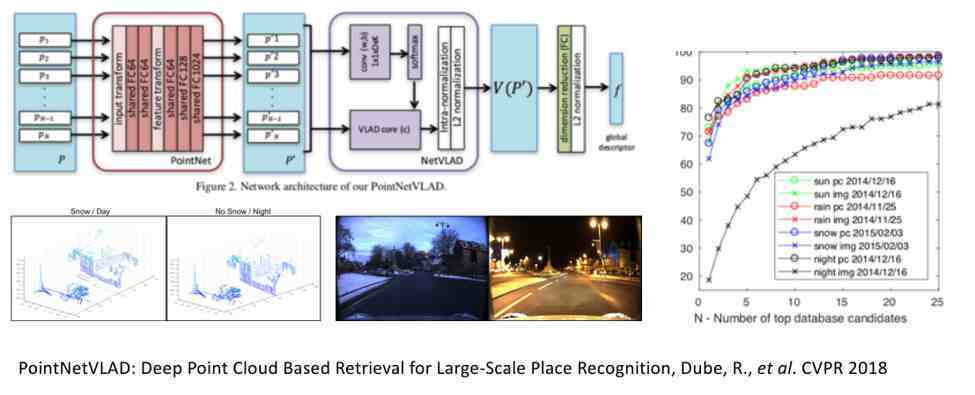
之前给大家介绍了如何利用二维和三维点云完成全局定位,下面介绍如何利用视觉信息来完成全局定位 。
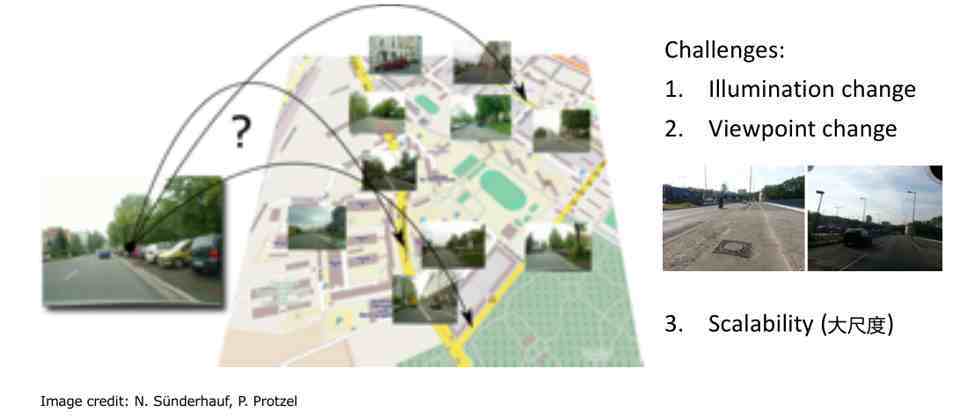
需要完成的定位工作可以通过这个画面去理解:给定一个地图,对地图关键帧和比较有特点的地方、地点进行视觉采样,即照一副照片,当下机器人观察到的是另外一个图像,这幅图像是不是在地图里面已经存储的某一幅图像?如果当下图像和地图中的图像成功匹配,那么也就完成了全局定位工作 。
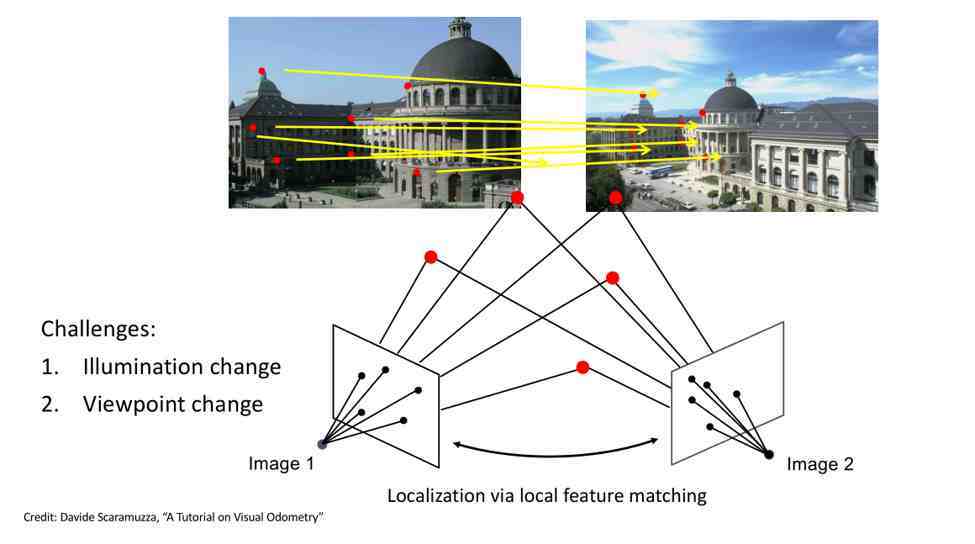
完成基于视觉的全局定位有几个挑战,挑战来源于:
首先是光照变化和视角变化的挑战:第一次和第二次访问不一定是同样的时间,光照和视角会发生变化 。举例来说,上面两幅图像问大家是不是来源于同一个地方?大家可能需要认真地看一会儿才能作出正确判断,通过比如说这个楼和这个楼是同样一座楼,还有路旁的树木 。
大尺度的挑战

这张地图里面包含了千万张关键帧图像,如何实时完成图像匹配是个巨大的挑战 。
如果不考虑计算复杂性,图像匹配工作原则上讲不是很难,给你两幅图像,看看是不是来自于同一个地点 。我们对第一和第二张图片进行点对点的特征匹配,如果有足够多的特征点匹配,我们就能初步判断图像来自于同一个位置 。当然,如果有光照和视角点变化时,特征点匹配则不是那么容易 。再有就是刚刚讲到的大尺度问题,如果地图包含很多不同的地点,一幅图像跟几万个地点匹配,这件工作的计算量是相当大的,对实时运算产生挑战 。
- 扫地机器人|扫地机器人哪个牌子好,扫地机器人排行榜
- 扫地机器人|扫地机器人排行榜,扫地机器人拖地效率排行盘点
- 信息技术背景下如何开展传统文化节日教育
- 机器人电影|世界十大机器人电影排行榜,机器人题材电影排名前十
- 测控技术与仪器专业个人工作简历怎么写?
- 摄影摄像技术专业求职简历怎么写?
- 毕业生求职信—汽车检测与维修技术专业怎么写?
- 信息技术专员毕业生个人简历如何写?
- 技术部经理辞职报告怎么写?
- 数控技术专业求职信写法怎么样?